Dans le cadre de mon diplôme d’ingénieur à l’IMT Mines Alès, j’ai eu l’opportunité de plonger au cœur de l’orchestration de conteneurs. L’objectif ? Démythifier Kubernetes en déployant mon propre cluster de A à Z. Au-delà de la simple installation, ce projet a été l’occasion de concevoir une architecture complète, de l’hyperviseur jusqu’au client léger, en mettant l’accent sur l’automatisation et la résilience.
Voici un retour d’expérience sur l’infrastructure mise en place et la méthodologie adoptée tout au long de ce projet.
L’Infrastructure : Du serveur local au travail nomade
Pour garder un contrôle total sur mon environnement, j’ai fait le choix de m’appuyer sur ma propre infrastructure de virtualisation.
Le socle matériel (Proxmox)
Le laboratoire tourne sur le second hyperviseur de mon infrastructure Proxmox personnelle. Il s’agit d’une machine dédiée spécifiquement à mes expérimentations, propulsée par un Intel Core i7 6700. Cela me donne la souplesse nécessaire pour allouer les ressources adéquates sans impacter mes autres services auto-hébergés.
Le poste de travail nomade
Pour interagir avec ce serveur, j’utilise un MacBook Neo en guise de client léger. Avec sa puce A18 Pro et sa batterie de 34Wh, son excellente autonomie me permet de travailler sur mon cluster depuis n’importe où, sans me soucier de la consommation énergétique.
Sécurité et connectivité (Netbird)
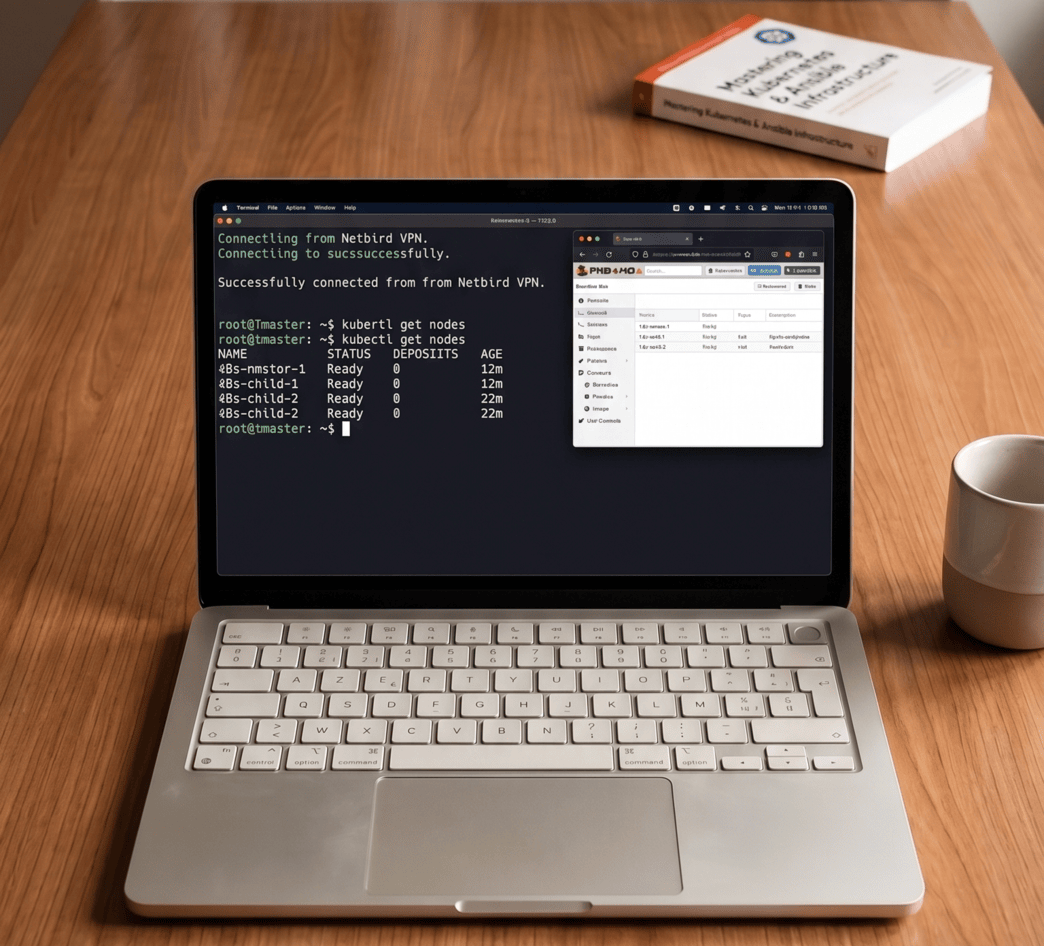
Afin de lier mon client léger à mon hyperviseur de manière sécurisée, j’ai mis en place un VPN maillé Zero Trust via Netbird. Cette architecture me permet d’accéder à mes nœuds virtuels comme si j’étais sur le réseau local, tout en garantissant un chiffrement de bout en bout, peu importe le réseau Wi-Fi sur lequel je suis connecté.
Automatisation du déploiement avec Ansible
Un cluster Kubernetes moderne ne se déploie pas « à la main », surtout dans une optique de reproductibilité. Pour ce laboratoire, j’ai défini une topologie standard composée de trois machines :
- 1 Nœud Maître (Control Plane) pour gérer l’état du cluster.
- 2 Nœuds Enfants (Workers) pour faire tourner les charges de travail.
L’OS de base choisi pour l’ensemble des nœuds est Rocky Linux, reconnu pour sa stabilité en environnement serveur.Plutôt que de configurer chaque machine individuellement, j’ai utilisé des playbooks Ansible. Cette approche d’infrastructure as code (IaC) m’a permis d’automatiser l’installation des prérequis matériels, la configuration du réseau, et l’initialisation du cluster Kubernetes de manière homogène et prédictible.
Méthodologie : Versionnement et filets de sécurité
L’apprentissage de Kubernetes implique de faire des erreurs, de casser des configurations et de recommencer. Pour avancer efficacement lors de mes sessions de TP, j’ai mis en place un flux de travail robuste :
Git pour le versionnement
Chaque étape de configuration, chaque playbook Ansible et chaque manifeste Kubernetes a été rigoureusement versionné. Cela offre une traçabilité parfaite de mes expérimentations et me permet de revenir en arrière sur une ligne de code précise.
Les Snapshots Proxmox
Le véritable « game changer » de mon workflow. Avant chaque manipulation critique sur le cluster (comme l’ajout du réseau CNI ou le déploiement des workers), je prenais un snapshot complet des machines virtuelles via le système de fichiers de mon hyperviseur. En cas de corruption du cluster (ce qui arrive inévitablement en phase d’apprentissage !), je pouvais restaurer l’état exact de mes machines en quelques secondes et reprendre mon TP sans frustration.
Bilan
Cette expérimentation a été extrêmement formatrice. Elle m’a permis de comprendre que la maîtrise de Kubernetes ne s’arrête pas à la simple ligne de commande kubectl, mais englobe tout un écosystème d’outils et de bonnes pratiques : gestion de l’infrastructure sous-jacente, automatisation des déploiements et sécurisation des accès.